既存DBで実現するベクトル検索:理論的な「下界フィルタ」より単純な「範囲検索」を選んだ理由
前回の記事(2月4日の一部)では、複雑化したLSH Overlap手法を捨て、数学的に扱いやすい「Pivot(参照点)」ベースの手法へ転換する話を書きました。
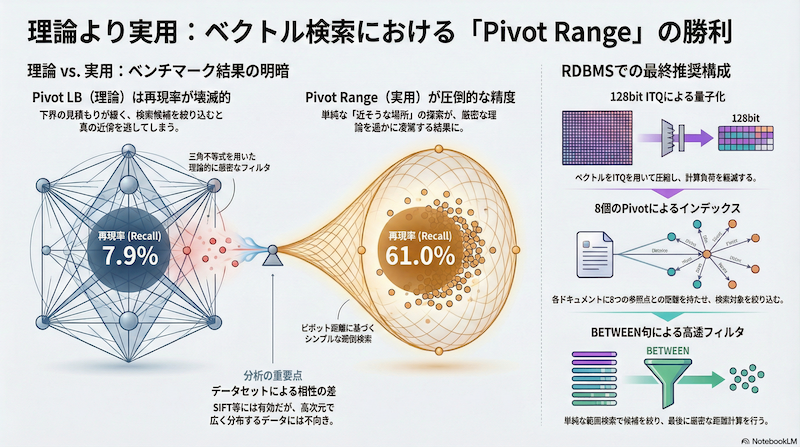
その後、理論的に美しい「三角不等式を用いた下界(Lower Bound)フィルタ」の実装と検証を進めていましたが、実験結果は予想外のものでした。 結論から言えば、「理論的に正しい厳密なフィルタ」は、「単純でヒューリスティックな範囲検索」に実用面で完敗しました。
今回は、一連のベンチマーク実験から得られた知見と、最終的にたどり着いた「最もシンプルで実用的な構成」について報告します。
理論の敗北:Pivot LB vs Pivot Range
Pivot手法に切り替えた当初、私の本命は Pivot LB (Lower Bound) でした。 これは三角不等式 $|d(q, p) - d(x, p)| \le d(q, x)$ を利用して、クエリ $q$ とデータ $x$ の距離の下界を見積もり、これを使って検索候補を足切り(フィルタリング)する手法です。理論上、False Negative(本来ヒットすべきものが漏れること)が発生しない美しい手法です。
しかし、プロジェクトに追加された Notebook 85 (Pivot LB Fair Comparison) の結果は残酷でした。
- Pivot LB: 下界の見積もりが「緩すぎる」ため、安全に検索しようとすると候補をほとんど絞り込めない。逆に候補数を無理やり絞ると、真の近傍点を取りこぼしてRecall(再現率)が壊滅する。
- Pivot Range: 「ピボットからの距離がクエリと近いデータを探す」という単純な範囲検索(
BETWEEN句など)。
同じ候補数になるように調整して比較したところ、Pivot RangeのRecallは61%に対し、Pivot LBはわずか7.9% という大差がつきました。高次元空間においては、厳密さを求めると探索範囲が広がりすぎてしまい、大胆に「近そうな場所」だけを探すヒューリスティックの方が圧倒的に効率が良いことがわかりました。
データセットとの相性:万能ではない
さらに、複数の標準データセットを用いた広範なベンチマーク(Notebook 72-75)の結果、この手法(ITQハッシュ + Pivot)には明確な「得意・不得意」があることが判明しました。
- 相性が良い:
SIFT-128,Fashion-MNISTなど。データが空間内で適度にクラスタリングされており、Pivotでの絞り込みが効く。これらはHNSWに迫る性能を出せます。 - 相性が悪い:
GIST-960,GloVe-100など。高次元で全体に広く分布しているデータ。これらは128bitへの圧縮やPivotでの絞り込みで情報落ちが激しく、実用的な Recall を出すのが難しい。
これは、ハミング距離と元のコサイン距離の相関(Spearman順位相関)を事前にチェックすることである程度予測できることもわかりました。
最終結論:シンプル・イズ・ベスト
これら一連の実験を経て、最終レポート (Notebook 00) を更新しました。
既存のRDBMSなどで、専用の拡張機能を使わずにベクトル検索を実装する場合の「ファイナルアンサー」は以下の構成です。
- 量子化: 128bit ITQ (Iterative Quantization)
- インデックス: 8個のPivotを選択し、各ドキュメントに8つの距離(INT/FLOAT)を持たせる。
- 検索: 単純な範囲検索 (
range_dist BETWEEN q_dist - 20 AND q_dist + 20) で候補を絞り、残った候補に対してのみ厳密な距離計算を行う。
複雑なOverlapインデックスや、計算コストの高いLBフィルタは不要です。 「HNSWが使える環境なら素直にHNSWを使うべき」ですが、そうではない制約環境下において、このアプローチは実装コストと性能のバランスが取れた現実解になります。
泥沼から抜け出し、ようやく自信を持って推奨できるシンプルな形に落ち着きました。